Real-TimeDataSyncforGenerativeAISystems

Real-time data synchronisation is essential for generative AI systems to deliver accurate and timely outputs. Unlike batch processing, which processes data at scheduled intervals, real-time pipelines ensure data is updated across systems almost instantly, often within milliseconds. This keeps AI applications like chatbots, recommendation engines, and dynamic pricing tools working with the most current information.
Key takeaways:
- Why it matters: Outdated data can reduce AI performance by up to 20%. Real-time updates improve accuracy and user satisfaction.
- How it works: Techniques like Change Data Capture (CDC), event streaming (e.g., Kafka), and API-driven synchronisation ensure low-latency, scalable data pipelines.
- Challenges: Building these systems requires overcoming hurdles like latency, scalability, and data quality issues.
- Best practices: Use tools like CDC for database changes, Kafka for event transport, and vector databases for serving data to AI models.
Real-time pipelines aren't just about speed; they ensure AI systems make decisions based on the most relevant information, reducing errors and improving outcomes. Whether you're upgrading legacy systems or building from scratch, focusing on low-latency, reliable data streams is the way forward.
Key Techniques for Real-Time Data Synchronisation
To tackle the hurdles of low latency, scalability, and integration, three key methods stand out for ensuring effective real-time data synchronisation in generative AI systems. These techniques directly address the need for timely and accurate data, which is crucial for maintaining optimal performance.
Change Data Capture (CDC) from Databases
CDC works by reading a database's transaction log rather than running repeated queries. This allows it to capture every insertion, update, or deletion in real time and stream these changes downstream. By focusing only on altered records, CDC avoids the inefficiencies of batch ETL processes, potentially cutting token and embedding API expenses by over 90% compared to re-indexing entire datasets.
For generative AI applications that depend on vector databases or retrieval-augmented generation (RAG) pipelines, this efficiency is especially critical. It ensures you're not wasting resources on re-embedding data that hasn't changed.
"The model is only as good as the data it reasons over. If that data is stale, no amount of prompt engineering can fix it." - Ricky Thomas, Data Expert, Streamkap
Event Streaming and Messaging Systems
After capturing changes, the next step is distributing them reliably to dependent systems like AI models, context stores, and search indices. Event streaming platforms, such as Apache Kafka, excel in this role. Kafka acts as a durable, ordered buffer, ensuring data flows smoothly between sources and consumers.
One of Kafka's standout features is its ability to handle high-throughput data streams without losing events, even if a consumer temporarily goes offline. Once the consumer is back online, it can pick up right where it left off. This decoupling of producers and consumers creates a robust, scalable system. Streaming architectures can reduce data freshness latency to under 10 seconds, a stark improvement over batch processes that may leave data outdated by hours.
API-Driven Synchronisation for External Data Sources
Not all data resides within internal databases. External sources like CRM systems, pricing feeds, inventory platforms, and third-party SaaS tools are often just as critical. For these, API-driven synchronisation is the go-to method, relying on webhooks and scheduled API calls.
Webhooks are ideal for pushing updates as they happen, avoiding the inefficiency of constant polling. When webhooks aren't available, managing rate limits becomes essential. Techniques like exponential back-off, queueing requests, and caching responses can help ensure smooth integration without overloading external APIs or introducing unnecessary delays into your AI's context window.
These synchronisation methods lay the groundwork for designing scalable, low-latency data pipelines, which will be explored further in the next section.
| Technique | Data Source | Typical Latency | Best Used For |
|---|---|---|---|
| Change Data Capture (CDC) | Internal databases | Milliseconds to seconds | Transactional records, product catalogues, user data |
| Event Streaming (e.g. Kafka) | Any upstream producer | Seconds | High-volume, multi-consumer data distribution |
| API-Driven Synchronisation | Third-party SaaS / external APIs | Seconds to minutes | CRM data, pricing feeds, external inventory |
Designing Scalable Real-Time Pipelines for Generative AI
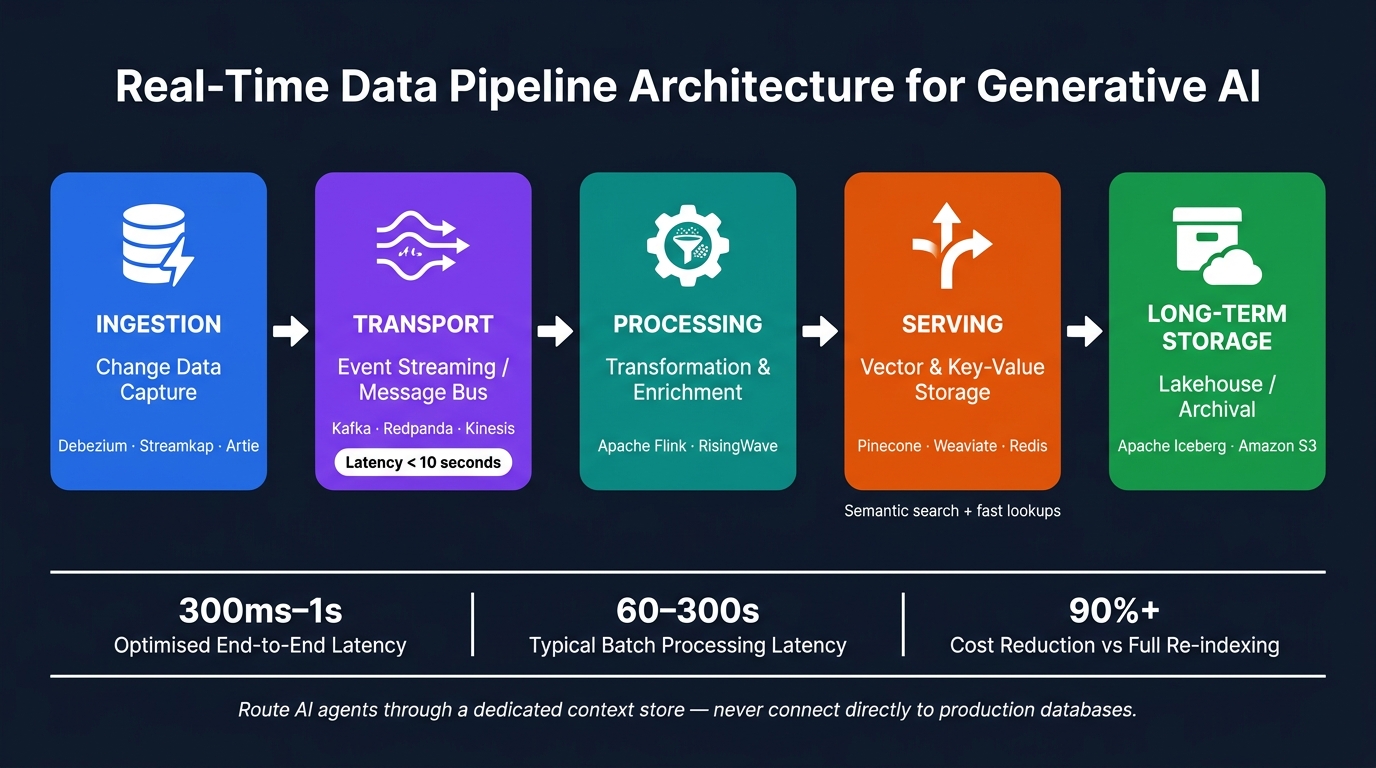
Real-Time Data Pipeline Architecture for Generative AI
How to Build a Real-Time Data Pipeline
A real-time data pipeline designed for generative AI typically consists of four key layers: ingestion, processing, serving, and storage. Each layer serves a specific purpose, ensuring smooth data flow and preparation for AI models.
The ingestion layer captures changes from source systems using tools like Debezium or Streamkap, which rely on Change Data Capture (CDC) techniques. These changes are passed through a transport layer - often powered by Apache Kafka or Redpanda - that acts as a durable and ordered event buffer. Once ingested, the data moves to the processing layer, where tools such as Apache Flink or RisingWave handle tasks like filtering irrelevant data, enriching records, and joining streams. This step ensures that only high-quality, relevant data reaches the AI model.
For serving, a dual-layer approach is recommended. Vector databases like Pinecone or Weaviate are ideal for semantic search, while key-value stores such as Redis are better suited for fast, exact lookups. It's crucial to avoid directly connecting your AI agent to production databases. Instead, route the data through a dedicated context store for better performance and security.
Here’s a quick breakdown of the layers and tools:
| Layer | Role | Recommended Tools |
|---|---|---|
| Ingestion | Change Data Capture | Debezium, Streamkap, Artie |
| Transport | Event streaming / message bus | Kafka, Redpanda, Kinesis |
| Processing | Transformation & enrichment | Apache Flink, RisingWave |
| Serving | Vector & key-value storage | Pinecone, Weaviate, Redis |
| Long-term Storage | Lakehouse / archival | Apache Iceberg, Amazon S3 |
This layered structure ensures that data is delivered to generative AI systems both efficiently and accurately, laying the groundwork for scalable, low-latency performance.
Achieving Scalability and Low Latency
When designing real-time systems, latency and reliability are critical factors to get right. Different AI applications have unique latency needs. For example, fraud detection systems often require responses in under 10ms, recommendation engines aim for sub-50ms responses, and conversational AI can typically handle up to 200ms. A common mistake is building a pipeline without a clear latency budget.
To support high-throughput demands without compromising speed, consider partitioning Kafka topics by logical keys like customer ID or product category. This approach allows multiple consumers to process data simultaneously. For global deployments, multi-region setups can further reduce latency by minimising the physical distance data needs to travel.
For processing, tools like Apache Flink excel at event-driven, sub-second processing, while Spark Structured Streaming often struggles with its micro-batch model, which can result in latencies of several seconds. A well-optimised real-time pipeline can achieve end-to-end latency between 300ms and 1 second, a significant improvement over the 60–300 seconds typical of batch processing.
Once the pipeline is operating at speed, the next challenge is ensuring it can recover gracefully from failures.
Building Resilience and Fault Tolerance into Real-Time Systems
Failures are inevitable in any system, but the ability to recover quickly and maintain data integrity is what separates a resilient pipeline from a fragile one.
Replayable logs (e.g., Kafka) and dead-letter queues (DLQs) are essential tools for building resilience. These mechanisms allow a failed consumer to restart without losing data and capture any malformed events for later analysis. Additionally, all writes to your vector store or cache should be idempotent - ensuring that replaying an event doesn’t create duplicates or inconsistencies.
Another critical practice is setting TTL (time-to-live) expiry on cached data. If the pipeline goes down, the AI system should signal that its data may no longer be current rather than relying on stale information. Including timestamps with every data chunk also helps both AI models and monitoring tools assess how fresh the data is.
"Once you see it working, batch ETL feels like checking the weather by reading yesterday's newspaper." - Artie
For teams managing multiple data streams, it’s wise to isolate pipelines by domain. For instance, a failure in syncing CRM data should not disrupt inventory feeds. This separation helps contain issues and speeds up recovery when problems occur. By focusing on these principles, you can build a system that not only performs well but also stands up to the challenges of real-world demands.
sbb-itb-1051aa0
Performance, Monitoring, and Governance
Key Metrics for Monitoring Real-Time Pipelines
Once your pipeline is operational, identifying the right metrics to track is just as crucial as its initial design. One of the most important metrics is end-to-end latency - this measures the total time it takes for a database row change to be used by the model during inference. Another critical metric is context age at inference, which calculates how old the retrieved documents are when compared to the query timestamp. If the context is consistently several minutes old, it suggests the data is outdated, even if individual pipeline components are fast.
Two additional metrics provide valuable insights. Consumer lag measures how far behind the pipeline is compared to the source database's transaction log (e.g., Postgres' WAL or MySQL's binlog), acting as an early indicator of bottlenecks. Meanwhile, change propagation completeness tracks the percentage of source changes that successfully make it downstream. A well-optimised pipeline should aim for at least 99.99% completeness. Monitoring error rates and dead-letter queues is also essential for comprehensive observability.
"The difference between a generative AI application that users trust and one they abandon often comes down to data freshness." - Ricky Thomas, CEO, Streamkap
The table below outlines latency thresholds for various use cases, providing benchmarks for monitoring rather than design:
| Use Case | Latency Threshold | Reason |
|---|---|---|
| Fraud Detection | < 10ms | Transactions need scoring before authorisation |
| Recommendation Engine | < 50ms | Personalisation must occur before page rendering |
| Dynamic Pricing | < 100ms | Prices should reflect demand at page load |
| Conversational AI/Chatbot | < 200ms | Humans expect minimal conversational delay |
| Predictive Maintenance | < 1s | Anomalies must reach the model before damage occurs |
While performance metrics are vital, ensuring the quality and consistency of data is equally important.
Maintaining Data Quality and Consistency
Performance monitoring is only part of the equation; preventing data quality issues is just as critical. Metrics can reveal problems, but proactive measures like in-flight validation - comparing expected and actual row counts at each pipeline stage - help catch data loss early. Tools like Apache Flink enable exactly-once processing, ensuring every event is processed precisely once, which avoids duplicates that could distort AI outputs.
Schema changes can create significant challenges. For instance, if a developer adds a new column to a production table and the pipeline isn’t prepared, it might crash or silently drop data. Using a Schema Registry with automated schema evolution can help avoid such disruptions. Additionally, re-embedding only new or modified records instead of reprocessing the entire dataset can save costs. With embedding APIs costing around £0.13 per million tokens, avoiding unnecessary processing can lead to notable savings.
"An agent operating on hour-old data doesn't just give a wrong answer, it executes the wrong action, and the consequence is real." - Confluent
Compliance and Privacy in Generative AI Workflows
After securing performance and data quality, compliance and privacy requirements must be addressed. In the UK, real-time generative AI systems must adhere to UK GDPR from the outset. This involves defining a lawful basis for each phase of AI use - such as development (e.g., training or fine-tuning) and deployment (e.g., real-time inference). Common lawful bases include consent, contract performance, and legitimate interests, all of which need clear documentation.
To protect privacy, implement input/output filters to remove personally identifiable information (PII) before data reaches vector stores or models. Maintaining audit trails by logging source timestamps and retrieval scores ensures accountability, especially in regulated sectors.
Automated decision-making introduces additional complexities. Under Article 22 of UK GDPR, if your pipeline supports fully automated decisions with legal or significant effects, users must have the option for human intervention and a clear explanation of the decision logic. The Information Commissioner's Office (ICO) has emphasised:
"If a system is too complex to explain, it may also be too complex to meaningfully contest, intervene on, review, or put an alternative point of view against." - Information Commissioner's Office (ICO)
Organisations should also account for the Data (Use and Access) Act, effective from 19 June 2025, which introduced updates to UK GDPR guidance concerning AI workflows. Reviewing data-sharing agreements in light of this legislation - particularly around controller and processor roles - is a prudent step for teams building production-grade AI systems.
Conclusion: Moving Forward with Real-Time Data Sync
Creating a dependable real-time data sync system for generative AI involves making well-thought-out architectural decisions. Using Change Data Capture to stream database transaction logs with sub-second latency and employing incremental embedding to handle only updated records - rather than reprocessing everything - lays a solid foundation for AI models to rely on.
In practice, this approach has delivered impressive results. For example, real-time agents with 75ms decision times have cut fraud losses by 62% in just one quarter. Similarly, AI-powered support systems using live data have reduced escalation rates from 22% to 7%. These outcomes highlight the transformative impact of using current data to boost AI reliability and practicality.
"Real-time data pipelines are not a nice-to-have for production GenAI applications. They are the foundation that determines whether your generative AI delivers accurate, current, trustworthy responses." - Ricky Thomas, Streamkap
For SMEs, a hybrid architecture is the way forward. This involves streaming only data sources where freshness directly affects decision quality, while keeping static or historical data on traditional batch schedules. This "minimum viable streaming surface area" approach strikes a balance between cost management and the responsiveness that modern AI applications need. It's worth noting that around 70% of AI projects fail because teams focus on technology first instead of addressing specific business issues. The starting point should always be identifying where outdated data is causing tangible problems.
Antler Digital helps SMEs move from legacy batch pipelines to production-ready real-time systems. Their five-phase process has unlocked up to £2.3m in upsell opportunities by synchronising CRM and billing data in real time. Whether you're building a system from scratch or upgrading an existing one, ensuring your AI operates with the freshest context will lead to results your users can trust and act on.
FAQs
What data should be real-time, and what can stay batch?
To strike the right balance between cost and performance, focus on real-time synchronisation for data that requires immediate updates. This includes things like session behaviour, inventory levels, transaction data, pricing changes, and fraud detection metrics - areas where even slight delays can affect AI-driven decisions or disrupt the user experience.
On the other hand, batch processing works well for less time-sensitive information, such as monthly user demographics or historical trends. Antler Digital creates workflows that are both scalable and efficient, ensuring critical data remains responsive without overspending on infrastructure for non-urgent tasks.
How do I set a realistic latency budget for my GenAI use case?
Start by identifying the specific requirements of your use case. For example, real-time chat applications often need end-to-end latency to stay below 500ms to ensure smooth interactions. Once you've established this, break the latency budget into distinct phases, such as:
- Network round trips
- Orchestration
- Data retrieval (like embedding and vector search)
- LLM Time to First Token (TTFT)
To keep things running smoothly, pay close attention to TTFT, aiming for it to fall between 200ms and 500ms. This is especially important for maintaining a responsive experience in interactive features. Use distributed tracing tools to monitor each stage and identify bottlenecks effectively.
How can I prevent stale or incorrect data from reaching the model?
To make sure your generative AI model always works with fresh and accurate data, consider using a real-time streaming setup. By employing Change Data Capture (CDC), you can stream database transactions as they occur, keeping your context store updated in real-time.
Incorporate in-flight validation to catch issues like schema drift or data quality problems before they cause trouble. Additionally, design your pipelines to handle tasks like filtering, deduplication, and reshaping data. This way, the records stay clean, streamlined, and ready for processing without delays.

Lets grow your business together
At Antler Digital, we believe that collaboration and communication are the keys to a successful partnership. Our small, dedicated team is passionate about designing and building web applications that exceed our clients' expectations. We take pride in our ability to create modern, scalable solutions that help businesses of all sizes achieve their digital goals.
If you're looking for a partner who will work closely with you to develop a customized web application that meets your unique needs, look no further. From handling the project directly, to fitting in with an existing team, we're here to help.