FutureofEvent-DrivenSynchronizationinAISystems

AI is moving away from slow, rigid systems to faster, asynchronous event-driven designs. This shift helps AI agents work independently, handle variable processing times, and scale efficiently. Key advancements include:
- Event-driven architecture: AI agents respond to events (e.g., task completions) instead of waiting for updates.
- Improved scalability: Systems like LangGraph 1.0 and AutoGen v0.4 use events to process tasks in parallel, avoiding bottlenecks.
- Real-time processing: Serverless platforms now support long-running tasks, cutting delays and improving resource efficiency.
- AI-driven infrastructure: Machine learning optimises event pipelines, predicts workloads, and reduces costs by up to 42%.
- Blockchain integration: Ensures data integrity and trust in decentralised AI systems.
These systems are cutting response times by 30–60% and enabling businesses to handle complex tasks more efficiently. From fraud detection to inventory management, event-driven designs are reshaping AI workflows.
Core Principles of Event-Driven Synchronisation
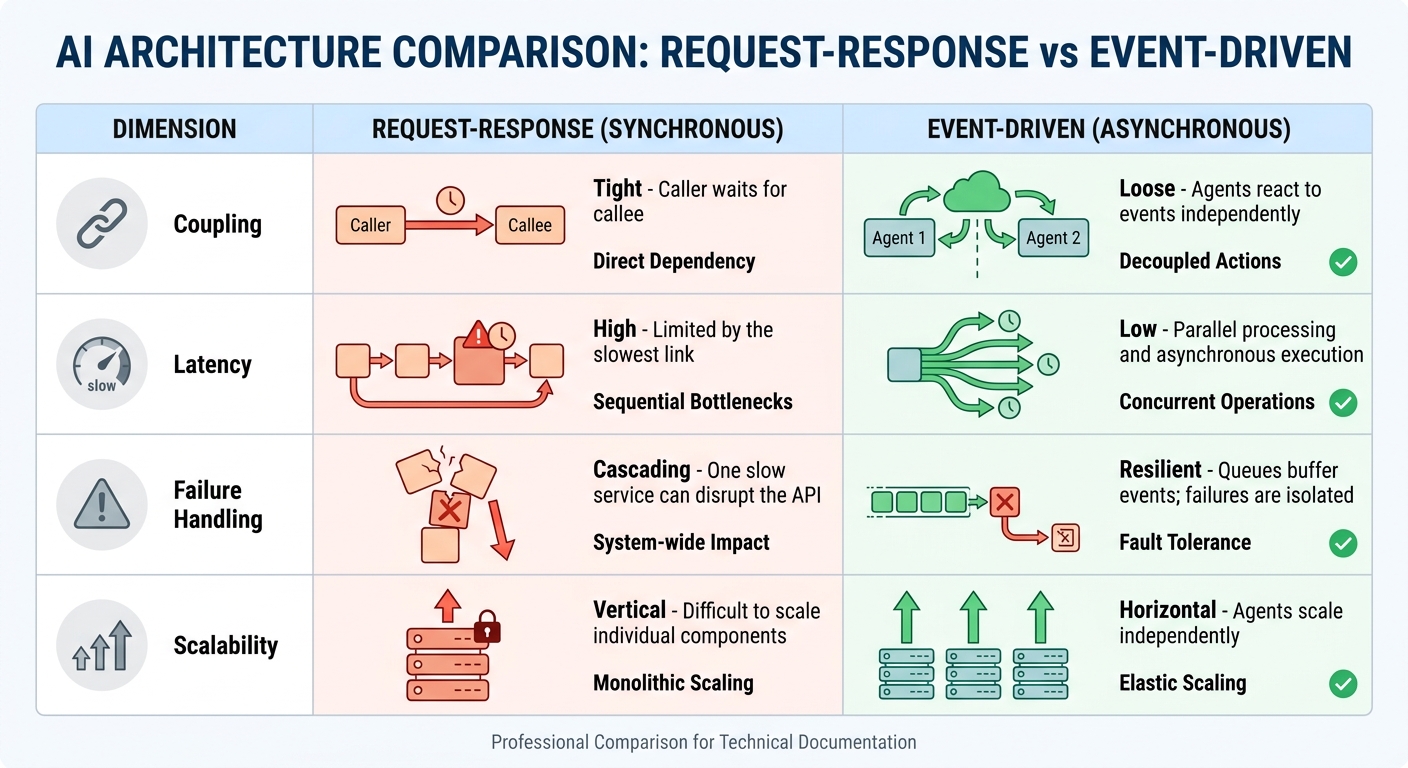
Request-Response vs Event-Driven Architecture in AI Systems
What is Event-Driven Synchronisation?
Event-driven synchronisation is a design pattern where AI agents or services respond to events - unchangeable records of state changes like OrderPlaced or InferenceCompleted - instead of constantly checking for updates. Think of it as a notification system: when an event occurs, the system sends out a signal, and any interested components act on it independently.
This approach relies on three main elements: producers, who publish events whenever there’s a state change; consumers, who subscribe to specific events and handle them as they arrive; and an event bus (tools like Kafka or RabbitMQ), which manages the routing and storage of events. This ensures that no slow consumer holds up the entire system, as events are stored until they’re ready to be processed.
Traditional synchronous systems struggle with AI workloads, especially when large language model (LLM) inference calls take 5–60 seconds, leading to connection timeouts or thread exhaustion. Event-driven architectures solve this by enabling asynchronous processing, eliminating the need for persistent open connections.
For more complex AI tasks, event-driven synchronisation enables workflow orchestration using Directed Acyclic Graphs (DAGs). For example, a single event like 'Document Uploaded' can trigger multiple asynchronous tasks, such as text extraction, embedding generation, and indexing.
This method not only separates system components for better efficiency but also supports scalability, as discussed below.
Benefits for AI Workflows
Event-driven synchronisation brings several advantages to AI systems. By enabling communication through the event bus instead of direct interactions, it simplifies adding new features - just subscribe to the relevant events. It also enhances resilience: the event bus buffers messages when a consumer fails, while Dead Letter Queues isolate problematic events, ensuring they don’t disrupt the system.
This architecture is particularly effective for handling LLM latency variability, as it prevents slow inference calls from overwhelming API gateways or exhausting server resources. Horizontal scaling becomes seamless - consumer instances can be added based on the depth of the event queue, allowing the system to adjust resource usage according to demand.
Teams adopting event-driven AI automation have reported operational response times improving by 30–60% once the system is fine-tuned. Additionally, managing Kafka deployments in-house typically requires over 2.3 full-time equivalents (FTEs) for upkeep, while fully managed cloud services reduce this to about 0.3 FTE.
| Dimension | Request-Response (Synchronous) | Event-Driven (Asynchronous) |
|---|---|---|
| Coupling | Tight: Caller waits for callee | Loose: Agents react to events independently |
| Latency | High: Limited by the slowest link | Low: Parallel processing and asynchronous execution |
| Failure Handling | Cascading: One slow service can disrupt the API | Resilient: Queues buffer events; failures are isolated |
| Scalability | Vertical: Difficult to scale individual components | Horizontal: Agents scale independently |
Another major advantage is auditability. Event sourcing creates an unchangeable log of all decisions made by agents, allowing for "time-travel debugging." This means developers can trace back to see what information an agent had at any given moment - critical for understanding why an AI system made a particular choice.
sbb-itb-1051aa0
Current Trends in Event-Driven Synchronisation
Serverless Architectures and Real-Time Processing
Serverless platforms have come a long way, evolving into what some are calling "Serverless 3.0." This new phase goes beyond just running functions - it eliminates infrastructure management entirely while enabling real-time event processing. Unlike earlier versions with strict execution limits (like the 15-minute cap), these updated architectures now support long-running tasks and durable workflows.
This shift is especially important for AI workloads, which often require asynchronous designs. Serverless event loops allow tasks to run in the background, providing immediate acknowledgements to users while handling complex AI processes behind the scenes.
"Serverless isn't just a runtime anymore; it's becoming the operating system of the cloud." – CloudServ.ai
A new concept, AI-Enhanced Event Orchestration (AIEO), is making waves. By using machine learning to predict workload patterns, AIEO optimises resource allocation in advance. Benchmarks show it can cut latency by 34%, improve resource use by 28%, and reduce infrastructure costs by 42%. This is a major improvement over reactive scaling, which often lags behind demand by up to 45 seconds.
The infrastructure supporting these advancements is also becoming more advanced. Services like AWS Lambda and Amazon Bedrock are now powering "agentic" AI. These systems involve autonomous agents that interpret events, reason about them, and generate new events to continue processing. Instead of being triggered by basic actions like file uploads, functions are now initiated by AI-specific events such as image classifications or vector similarity matches. These developments are paving the way for deeper AI involvement in event-driven systems.
AI Integration in Event Pipelines
Event-driven systems are increasingly leveraging AI not just to process events but also to manage the infrastructure itself. For example, machine learning-based Dead Letter Queue (DLQ) systems can automatically identify failure types - like exceeding context windows or hitting rate limits - and reroute them for resolution. This prevents one problematic event from clogging up the entire pipeline.
The market for agentic AI is growing rapidly. Valued at approximately £8.5 billion in 2026, it is projected to skyrocket to £155 billion by 2034. Gartner predicts that by the end of 2026, 40% of enterprise applications will feature task-specific AI agents, up from less than 5% in 2025. However, the complexity of this technology means that about 40% of agentic AI projects are expected to be abandoned by 2027.
Frameworks are adapting to meet these new challenges. AutoGen v0.4, for instance, employs an actor model where agents act as event handlers, emitting typed messages. LangGraph 1.0 uses a BSP/Pregel channel model with PostgreSQL-backed checkpoints, while CrewAI Flows relies on a decorator-based state machine. These systems embody an "always listening" approach, where agents are continuously monitoring events and creating an immutable audit trail.
"The key shift is from agents that are called periodically to agents that are always listening - consuming resources proportional to event volume, not time elapsed." – UData
This shift to "always listening" fundamentally changes business automation. Instead of relying on scheduled tasks, systems now respond to events in real time, scaling resources dynamically to match demand.
Blockchain for Trust and Data Integrity
Blockchain is emerging as an essential tool for building trust in decentralised, event-driven AI systems. By recording cryptographic hashes of datasets and metadata on an immutable ledger, blockchain ensures data integrity across distributed pipelines.
"A blockchain-based traceability mechanism guarantees transaction authenticity, immutability, and compliance, which is essential for establishing trust in decentralised IoT data ecosystems." – Journal on Wireless Communications and Networking
This technology becomes even more effective when combined with edge computing. Blockchain-integrated edge frameworks can synchronise data reliably, even in environments with intermittent connectivity, without relying on a centralised platform. By using Merkle tree verification alongside blockchain, these systems maintain strong communication across distributed nodes.
Research is also exploring the combination of blockchain with Trusted Execution Environments (TEEs) to create fair data exchange systems. These frameworks use decentralised attribute-based encryption (DABE) and blind watermarking - allowing watermark extraction without accessing the original data - to enhance traceability and prevent unauthorised data sharing. Smart contracts further automate governance, for instance, by tagging sensitive data in event streams.
"Blockchain-integrated edge computing frameworks can significantly improve the efficiency, transparency, and trustworthiness of data trading processes." – Springer Nature
Platforms are now employing Metadata Change Logs (MCL) with Kafka-based streams, which are recorded on blockchain. This creates permanent, auditable records of AI decision-making contexts. By adding this trust layer, systems can ensure verifiable decision trails while scaling dynamically, complementing the advancements in serverless real-time processing and AI orchestration.
Implementation Challenges
Deploying event-driven synchronisation in production AI systems is no small feat. These setups face a mix of theoretical and practical obstacles, ranging from distributed system constraints to issues like cost, security, and regulatory compliance.
Maintaining Data Consistency Across Regions
Distributed systems are bound by the CAP theorem, which makes achieving exactly-once delivery across networks nearly impossible. Instead, most systems settle for at-least-once delivery paired with idempotent receivers to manage duplicates. But even with these measures, physical distance and clock skew create additional hurdles. For example, latency becomes a major issue in pipelines spanning continents like North America and Asia. Meanwhile, even minor time discrepancies between servers can disrupt event order - issues that tools like NTP simply can't fully resolve.
The dilemma between strong consistency (ACID) and eventual consistency is a tough one. Global ACID enforcement is hampered by latency, while eventual consistency risks data conflicts when regions update the same record simultaneously. Testing has shown that uncoordinated API calls can increase latency by over tenfold. However, introducing an "Event Spine" for coordination reduced production incidents by 71% in its first quarter of use, proving the value of structured synchronisation.
"The problem was not the agents... The problem was the missing coordination infrastructure between them, what I now call the 'Event Spine'." – Sreenivasa Reddy Hulebeedu Reddy, Former Lead Software Engineer, AT&T Services Inc.
Regulations like GDPR and CCPA further complicate matters by restricting cross-region data movement. This often necessitates complex partitioning or anonymisation workflows, making synchronisation logic even trickier. To tackle these challenges, systems are increasingly adopting Conflict-free Replicated Data Types (CRDTs), such as Observed-Remove Sets, which help ensure data convergence without central locks. Another approach involves using unique event IDs as storage keys in a deduplication store (e.g., Redis) with a 24–72 hour TTL to avoid processing duplicates.
Scaling Under High Event Loads
Handling high event volumes is another major challenge, particularly in AI-heavy workflows. For instance, a single Generative AI inference call can take anywhere from five to sixty seconds, meaning synchronous HTTP calls are simply impractical under heavy load.
To manage this, decoupling producers from consumers with message queues (e.g., AWS SQS, RabbitMQ, or Kafka) is a reliable solution. These queues can buffer traffic spikes, preventing system crashes. Consumers can then scale horizontally based on queue depth, adding worker instances as needed to clear backlogs.
Other strategies, like semaphore-based concurrency limits, token bucket rate limiting, and queue depth monitoring, help prevent downstream AI services from being overwhelmed or exceeding API rate limits. Without such controls, organisations risk burning through tokens quickly or hitting financial roadblocks.
"Every call burns tokens and compute, so wasted effort translates directly into real money." – Microsoft
Retry strategies also play a crucial role. Adding jitter to retries can reduce retry spikes by over 80% in distributed systems. Similarly, webhook receivers should respond with a 200 OK within 2–3 seconds, offloading payloads to a queue for asynchronous processing to avoid timeouts. Using an event spine for context propagation can cut agent CPU usage by up to 36%, as it eliminates redundant data fetching across agents. These measures ensure systems remain stable and efficient under pressure.
Security and Privacy Concerns
Event-driven systems bring unique security challenges, especially in sensitive industries like FinTech or Crypto. For example, malicious actors could send arbitrary payloads to webhook endpoints, triggering unauthorised AI actions or injecting false data. To prevent this, HMAC-SHA256 signatures should be used to verify payload authenticity, with constant-time comparison functions (e.g., timingSafeEqual) to guard against timing attacks.
Replay attacks are another risk. Attackers could capture valid signed requests and replay them later to cause duplicate actions or corrupt state. To counter this, timestamps should be included in signed data, and requests outside a 5-minute window should be rejected to account for clock skew.
In multi-agent systems, strict data governance is critical. Without it, agents might access sensitive topics they shouldn’t, such as a finance agent pulling HR data. Centralised control through topic-level Access Control Lists (ACLs) at the message broker level can enforce stricter access rules. Additionally, applying the Single-Writer Principle for critical entities like payments ensures only one agent has write permissions, reducing the risk of conflicts.
To avoid duplicate side effects caused by LLM non-determinism in at-least-once delivery systems, idempotency keys - created by combining task_id and action_type - can be applied. Addressing these security and privacy challenges is essential for building scalable and reliable event-driven AI systems.
How Event-Driven Synchronisation is Shaping AI Systems
Event-driven synchronisation is changing the way AI systems operate by shifting from traditional polling methods to real-time reactions. Instead of relying on scheduled tasks, AI agents now respond instantly to events as they occur. This approach reduces latency and ensures that computing resources are used based on the volume of events rather than the passage of time.
This method has proven to be highly effective. Operational response times have been cut by 30–60%, and automated incident responses can now reduce the mean time to resolution (MTTR) from 45 minutes to under 10 minutes. Unlike older deterministic systems that rely on rigid if/else logic, event-driven AI agents are capable of reasoning through new inputs and managing edge cases that would normally disrupt traditional automation.
"The key shift is from agents that are called periodically to agents that are always listening - consuming resources proportional to event volume, not time elapsed." – UData
To further enhance performance, message queues like AWS SQS or RabbitMQ are often used to decouple processes. These queues buffer incoming events, protecting AI systems from being overwhelmed by sudden spikes in traffic. Many systems now use a three-tier synchronisation model:
- Tier 1: Handles critical data (e.g., inventory) with latency under 500ms.
- Tier 2: Manages updates like pricing within 5–15 minutes.
- Tier 3: Handles less frequent changes, such as product descriptions, through batch processing.
Benefits for SMEs
For small and medium-sized enterprises (SMEs), event-driven synchronisation offers solutions to operational challenges that previously required heavy infrastructure investments. Managed event streaming services have made this technology more accessible, with costs ranging from £160 to £640 per month. For instance, Amazon EventBridge charges around £0.80 per million events.
The benefits for SMEs are clear. Take a mid-sized SaaS company handling 10,000 support tickets a month: event-driven automation could resolve 60% of routine queries, freeing up 800 hours of support capacity. Real-time responsiveness is particularly crucial in scenarios like sudden demand spikes. For example, TikTok Shop is expected to reach $23.4 billion (roughly £18.5 billion) in US GMV by 2026. In such cases, event-driven inventory synchronisation - with end-to-end latency under 500ms - can prevent overselling during viral sales surges.
"A fraud detection model that runs every 15 minutes is not a fraud detection model - it is a fraud reporting model." – Exponential Tech
SMEs can adopt a three-tier approach to synchronisation:
- Use real-time systems for critical data like inventory and orders.
- Apply near-real-time processing for pricing updates.
- Rely on batch synchronisation for less critical changes.
Building an event-driven pipeline typically requires 40–80 hours of development time. Managed services such as Amazon EventBridge, Google Pub/Sub, or Confluent Cloud simplify deployment. Even in fully event-driven systems, periodic batch reconciliation (e.g., every four hours) remains valuable for catching missed events or network issues.
These operational improvements are setting the stage for new research directions that will reshape AI system architectures.
Future Research Directions
As event-driven architecture continues to evolve, researchers are tackling the dynamic challenges it presents in AI systems. Frameworks like AutoGen v0.4 are adopting actor models with typed message passing, allowing agents to function as independent event handlers. This approach ensures location transparency and isolates failure domains.
Standardisation is also advancing. Protocols such as Google's Agent2Agent (A2A) for vendor collaboration and Anthropic's Model Context Protocol (MCP) for tool integration are enabling secure, real-time data sharing across different AI systems. Streaming platforms like Confluent and Apache Flink are now integrating support for long-running AI agents.
Meanwhile, there’s growing interest in Kappa architecture, a stream-only model that replaces traditional ETL pipelines with continuous processing. Machine learning is also being applied to improve Dead Letter Queue (DLQ) management, classifying errors and routing them to appropriate workflows. Lastly, OpenTelemetry GenAI conventions are helping standardise observability for large language models (LLMs), improving monitoring of agent traces and complex payloads. This is a vital step as AI systems become increasingly autonomous and reliable.
Conclusion
Event-driven synchronisation is reshaping how AI systems operate, offering businesses a chance to achieve faster and more efficient outcomes. By enabling real-time processing, companies are seeing operational response times drop by 30–60% and incident resolution times shrink from 45 minutes to under 10 minutes. This approach allows AI agents to function as "always listening" systems, using resources based on event volume rather than time, which helps cut down on unnecessary computing costs.
The adoption of standardised protocols like Google's A2A and Anthropic's MCP, along with built-in agent support for streaming platforms, signals an ecosystem that's becoming more refined. With nearly half (48%) of senior IT leaders ready to integrate AI agents into their operations, event-driven architecture is laying the groundwork for a more flexible and responsive automation landscape. Moving from rigid, pre-set workflows to adaptable, reasoning-based systems represents a fundamental shift in how businesses handle automation.
Whether it's tackling fraud as it happens, managing sudden surges in demand, or coordinating complex, multi-agent tasks, event-driven synchronisation turns AI into an active, responsive force. This shift equips organisations to handle the challenges of modern business with greater agility and precision.
FAQs
When should I use event-driven synchronisation instead of request-response?
When your system demands decoupling, scalability, and resilience, especially in environments with high latency, multiple agents, or asynchronous operations, event-driven synchronisation is the way to go. Unlike the traditional request-response model, which depends on direct, synchronous communication, event-driven architecture allows components to respond to events asynchronously. This approach enhances both flexibility and fault tolerance.
It’s particularly useful in AI-driven workflows, where managing complex, multi-agent systems requires parallel processing and the ability to scale components independently. By leveraging this model, you can handle intricate operations more efficiently without being tied to rigid, synchronous interactions.
How do you handle duplicate or out-of-order events in AI workflows?
Managing duplicate or out-of-sequence events is essential for ensuring reliable AI workflows. One effective approach is using idempotent receivers, which can identify and ignore duplicate events by leveraging unique identifiers, such as idempotency keys.
To address out-of-order events, techniques like sequence numbers or logical timestamps can be applied to maintain the correct event order. Beyond these methods, strategies like event sourcing and event replaying play a key role in preserving system consistency and accuracy, especially in event-driven AI architectures. These approaches ensure that workflows remain dependable, even in complex scenarios.
What’s the quickest way for an SME to adopt event-driven AI safely?
The quickest and most secure way for a small or medium-sized enterprise (SME) to embrace event-driven AI is through a phased strategy. Begin with small pilot projects aimed at automating repetitive, high-impact tasks. This approach allows for a controlled rollout while minimising risks. Gradually expand the use of AI, keeping a close eye on its performance and ensuring adherence to UK data protection laws, such as GDPR. Incorporating event-driven architecture patterns, like message queues, can also enhance scalability and safety by enabling automated error handling.

Lets grow your business together
At Antler Digital, we believe that collaboration and communication are the keys to a successful partnership. Our small, dedicated team is passionate about designing and building web applications that exceed our clients' expectations. We take pride in our ability to create modern, scalable solutions that help businesses of all sizes achieve their digital goals.
If you're looking for a partner who will work closely with you to develop a customized web application that meets your unique needs, look no further. From handling the project directly, to fitting in with an existing team, we're here to help.