ContinuousAIImprovementwithFeedbackLoops

AI systems lose relevance over time without updates. Feedback loops solve this by continuously improving models based on real-world data. They track outputs, gather user input, and adjust models to address issues like distributional drift. This keeps AI systems effective and aligned with changing user needs.
Key takeaways:
- Feedback types: Explicit (e.g., user ratings), implicit (e.g., behaviour patterns), and system-level (e.g., error rates).
- Real-world examples: GitHub Copilot improved code completions by 30% using signals from 400,000 samples. NVIDIA reduced latency by 70% by fine-tuning models based on 30,000 interactions.
- Human oversight: Risk-based routing ensures humans intervene only when necessary, reducing costs by up to 55%.
- Data pipelines: Scalable systems ensure feedback is collected, processed, and used for retraining without breaching compliance standards.
To implement feedback loops:
- Start with a clear, measurable task.
- Collect explicit and behavioural signals.
- Build a scalable data pipeline for processing and retraining.
Feedback loops turn user interactions into opportunities for continuous improvement, ensuring AI systems remain effective and reliable.
Core Types of AI Feedback Loops
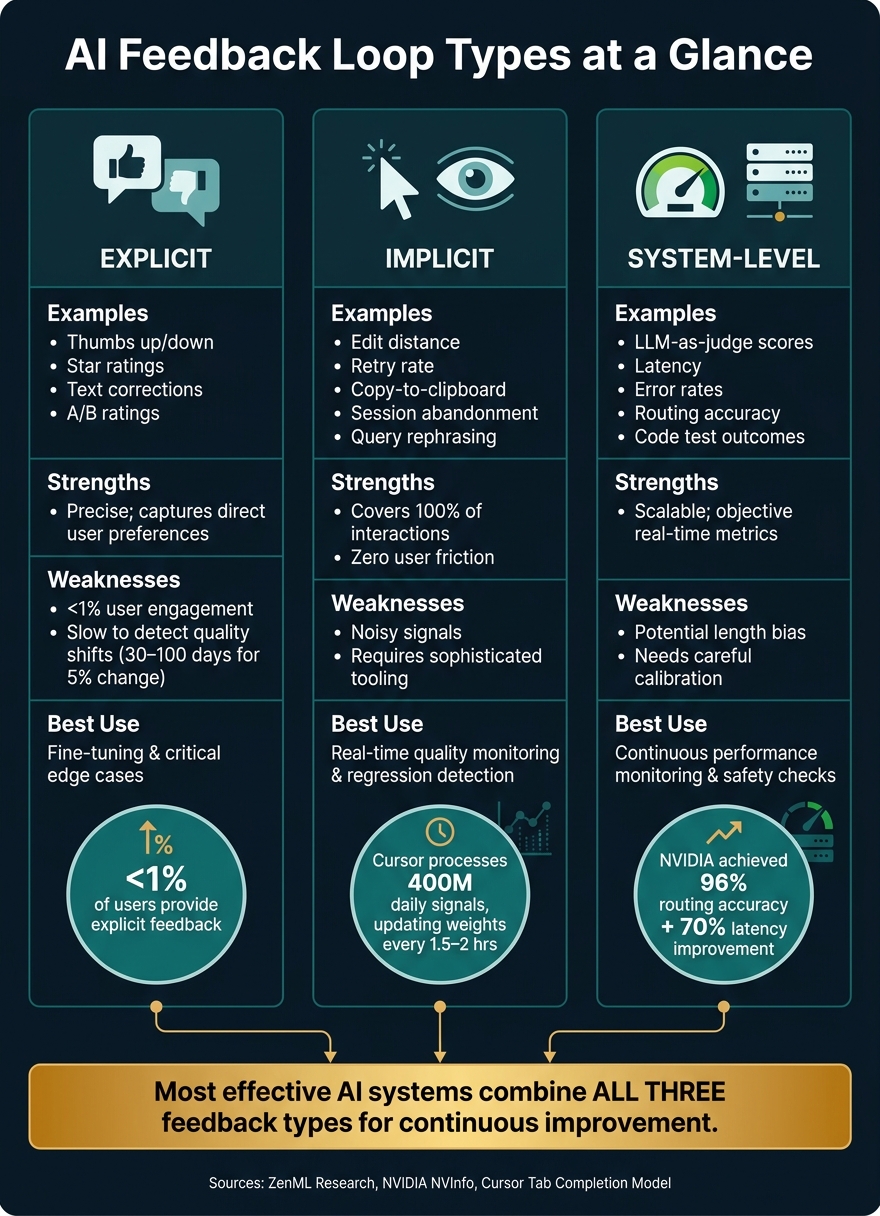
AI Feedback Loop Types: Explicit vs Implicit vs System-Level
Explicit, Implicit, and System-Level Feedback
AI systems rely on three key feedback types - explicit, implicit, and system-level - to gather insights and ensure optimal performance.
Explicit feedback captures direct user input, such as thumbs-up, star ratings, or corrections. While this type is highly precise, it faces a significant limitation: user engagement is typically low, often below 1%. This low volume can make it challenging to detect even minor quality shifts. For instance, in a product with 1,000 daily active users, identifying a 5% quality change with statistical confidence might take 30 to 100 days. As Tian Pan, Engineer-Founder, aptly states:
"The 30-day gap isn't a measurement inconvenience - it's a product liability."
On the other hand, implicit feedback captures passive behavioural signals. These include metrics like the extent of edits to AI suggestions (edit distance), whether users rephrase queries within a short window, or actions like copying content to the clipboard. Such signals offer a continuous stream of data reflecting real user behaviour. For example, Cursor's Tab completion model processes acceptance and rejection signals from 400 million daily requests, updating its weights every 1.5 to 2 hours.
Finally, system-level feedback provides automated, objective metrics. This includes data like latency, error rates, routing accuracy, or LLM-as-judge scores, which evaluate outputs against specific criteria. Techniques such as Reinforcement Learning from Verifiable Rewards (RLVR) use these metrics to train models, focusing on measurable outcomes like whether a code snippet passes a unit test.
How Feedback Fits into the AI Lifecycle
Feedback plays a central role in the continuous AI lifecycle, feeding into every stage of model development and refinement. The process begins with capturing raw signals, such as logs and traces, which are then sampled and labelled to create preference pairs. These pairs are essential for retraining pipelines, like Direct Preference Optimisation (DPO). Once retrained, models are validated in shadow mode - tested with live traffic without impacting users - before full deployment.
A practical example of this lifecycle is NVIDIA's NVInfo system. Between late 2024 and early 2025, the team analysed 30,000 employee interactions over three months. System-level feedback revealed specific failure categories: routing errors accounted for 5.25%, and query rephrasal errors for 3.2%. Using these insights, they replaced a Llama 3.1 70B routing model with a fine-tuned 8B variant, achieving 96% routing accuracy and a 70% improvement in latency.
"The flywheel effect compounds faster than most teams expect. Once you have even a modest feedback loop in place, the quality improvements accelerate." – ZenML Research
Feedback Types Compared
Choosing the right feedback strategy depends on your goals. Explicit feedback works best for aligning models in high-stakes scenarios, implicit feedback is ideal for monitoring quality in real time, and system-level feedback ensures reliable performance at scale. Most effective systems combine all three.
| Feedback Type | Examples | Strengths | Weaknesses | Best Use Case |
|---|---|---|---|---|
| Explicit | Thumbs up/down, star ratings, text corrections, A/B ratings | Precise and captures direct user preferences; ideal for training | Limited volume and may deter users | Fine-tuning and critical edge cases |
| Implicit | Retry rate, edit distance, copy-to-clipboard, session abandonment, task completion | Covers all interactions with no user friction; reflects actual behaviour | Signal can be noisy; requires sophisticated tools | Real-time quality monitoring and detecting regressions |
| System-Level | LLM-as-judge scores, code test outcomes, routing accuracy, latency, error rates | Scalable and provides objective, real-time metrics | Can introduce biases (e.g., length bias); needs careful calibration | Continuous performance monitoring and safety checks |
One simple yet effective tip: when collecting explicit thumbs-down feedback, include a quick reason picker with options like "wrong info" or "too long." This can boost completion rates to around 60%, compared to less than 12% for open-ended free-text feedback.
The next sections will explore how to design these feedback systems with strong human oversight and scalable data pipelines.
Designing Feedback Mechanisms with Human Oversight
Principles for Human Oversight in Feedback Loops
Effective oversight doesn’t mean constant human involvement - it’s about stepping in only when necessary. One practical method is escalation-triggered oversight. Here, the AI operates independently until it encounters low confidence, ambiguous inputs, or is about to take a high-stakes action, prompting human review.
A key strategy for this is risk-based routing. By categorising tasks into different tiers - ranging from low-risk outputs that need no review to critical decisions requiring immediate senior input - organisations can cut human review costs by 40–55% while maintaining high standards. The table below illustrates this in action:
| Review Tier | Risk Level | SLA | Reviewer Requirement | Example Use Case |
|---|---|---|---|---|
| T0 | Low | Auto | None | Simple summaries, low-impact Q&A |
| T1 | Medium | < 4 hours | 1 Reviewer | General customer support responses |
| T2 | High | < 2 hours | 2 Reviewers | Legal, financial, or medical decisions |
| T3 | Critical | Immediate | Senior SME | Safety incidents, regulatory compliance |
Beyond categorisation, teams are encouraged to move away from a gatekeeping mindset and adopt a "Shared Intelligence" approach. This means treating every human correction as a learning opportunity for the AI.
"The era of simply monitoring AI agents has passed... A true feedback loop transforms every human interaction into a specific, actionable learning opportunity." - Jarvis Helpdesk AI
These principles not only optimise feedback collection but also enhance how web applications incorporate human oversight.
Feedback Capture in Web Applications
To align with these oversight principles, feedback capture in web applications should be seamless yet thorough. The aim is to make providing feedback as easy as a single tap or an inline edit, avoiding disruptions like lengthy forms.
One of the most effective methods is correction capture. When users edit AI-generated drafts, capturing the "diff" between the original and the revised versions offers a clear training signal for refining the AI. Pair this with a quick reason selection to keep feedback structured and actionable.
Equally important is recording the full context of feedback. This includes the prompt, model output, UI state, retrieved sources, and model version. Such comprehensive data ensures reliable retraining. Additionally, silent-churn detection - tracking subtle behaviours like repeated query rephrasing or feature disabling - can highlight dissatisfaction that isn’t explicitly reported.
"Without visibility into how agents behave, why they fail, and where they succeed, autonomy becomes reckless. With it, autonomy becomes an evidence-based progression." - Alok Thatikunta, Co-founder & CTO, Pulse
By combining these strategies, teams can ensure continuous AI improvement, from capturing feedback to refining human intervention.
Human Review in Agentic Workflows
In agentic systems - where AI performs a series of actions instead of just generating single responses - human review needs to be a built-in feature. One essential aspect is stateful checkpointing. When an agent escalates a task to a human, it should preserve its entire execution state, including conversation history, tool calls, and intermediate results. This allows the human reviewer to pick up right where the AI left off.
Another key feature is asynchronous escalation. By using message queues, the AI can continue processing without being slowed down by human response times. This approach ensures smooth operations and avoids bottlenecks that could turn an autonomous system into a sluggish support tool.
For example, a FinTech company implemented this method in early 2026, introducing human-in-the-loop queues for high-risk tasks. Within six weeks, they eliminated P0 incidents and improved first-response times by 31%. Similarly, Antler Digital embedded approval checkpoints and correction pipelines into their workflows for SMEs, ensuring humans only stepped in at critical decision points rather than being bogged down by routine approvals.
"The goal is not maximum human involvement. The goal is the right human involvement." - Antoine Buteau
Building Scalable Feedback Data Pipelines
End-to-End Feedback Data Flow
Once you’ve established human oversight, the next step is ensuring feedback data makes its way to the systems that need it. A scalable pipeline works across four key layers: ingestion, processing, evaluation, and training. Each layer has a specific role, and any breakdown along the way can hinder progress.
The starting point for this process is instrumentation. As Harrison Chase, CEO of LangChain, explains:
"In software, the code documents the app; in AI, the traces do."
This means capturing every LLM call, tool invocation, and metadata detail - like latency, token counts, and model versions - using a stable trace ID. Without this, it’s impossible to reliably link feedback to the system behaviour that prompted it. From there, signals - both explicit (like user corrections or ratings) and implicit (like query rephrasing or session abandonment) - are sent to a processing layer. This layer cleans, samples, and routes the data for evaluation.
For evaluation at scale, automated scoring using an LLM-as-judge can handle most of the workload, while human reviewers step in for cases that are either uncertain or high-stakes. This seamless flow of data lays the groundwork for solid engineering practices in feedback handling.
Data Engineering Considerations
Building on the data flow, precise engineering ensures both data quality and compliance. This is especially critical under regulations like the UK and EU GDPR. Personally Identifiable Information (PII) must be redacted before entering any training pipeline, and regex alone won’t cut it. Tools like Microsoft Presidio, which can detect over 50 entity types (such as names, addresses, and national insurance numbers), offer much better reliability.
Here’s a breakdown of the core engineering requirements for a production-ready feedback pipeline:
| Factor | Requirement | Implementation Detail |
|---|---|---|
| Event Schema | Standardised Tracing | Use OpenTelemetry GenAI conventions for prompts, retrievals, and tool calls |
| Compliance | PII Redaction | Automate detection of 50+ entity types before storing data |
| Retention | Time-limited Storage | Retain data for 12 months to minimise regulatory risks and prioritise recent data |
| Quality Control | Data Quality Gates | Validate sample size and class balance before retraining |
| Governance | Model Registry | Maintain full version history with one-click rollback options |
A 2025 Gartner survey revealed that 63% of organisations either lack or are unsure about their data management practices for AI. Addressing these fundamentals early on can help avoid costly problems down the road.
Retraining Strategies for Continuous Improvement
Once you’ve got clean, compliant data in place, retraining strategies can use this feedback to drive ongoing improvements in AI performance. The biggest gains often come from harness mutation - adjusting prompts, routing logic, and tools without altering the model’s weights. A great example comes from Harvey, a legal AI platform. In May 2026, it used an agent to iteratively refine its system harness based on rubric-graded feedback across 12 legal tasks. The result? Task success rates jumped from 40.8% to 87.7%, all while keeping model weights completely unchanged.
When retraining is necessary, the best approach depends on factors like your infrastructure, budget, and how quickly you need results. Here’s how different strategies compare:
| Strategy | Complexity | Cost | Suitability for SMEs |
|---|---|---|---|
| Prompt Engineering | Low | Low | High - quick iterations but limited by model context and capability |
| Trajectory Tuning | Medium | Low | High - uses dynamic few-shot examples; no weight updates needed |
| LoRA Fine-Tuning | High | Medium | Medium - efficient parameter updates but requires GPU infrastructure |
| DPO / RLHF | Very High | High | Low - ideal for alignment but needs high-quality preference pairs |
| Harness Mutation | Medium | Low | High - updates tools and logic; weights stay frozen; easy to audit |
Additionally, active learning can achieve similar accuracy improvements with just 10–30% of the data volume needed for random sampling. This creates a compounding effect:
"The flywheel effect compounds faster than most teams expect. Once you have even a modest feedback loop in place, the quality improvements accelerate." - ZenML Analysis
sbb-itb-1051aa0
Monitoring and Governance for AI Feedback Loops
Metrics for Monitoring AI Performance
Once your pipeline is operational, keeping a close eye on both model performance and user behaviour is crucial. This means tracking two distinct layers: performance metrics like accuracy, latency, and error rates, and behavioural signals that reveal how users are interacting with the system. Monitoring these together helps pinpoint errors and refine the system continuously.
Behavioural signals are particularly revealing. For example, if users frequently retry or reformulate queries, the model might be struggling to deliver accurate results on the first attempt. Similarly, a high edit distance - indicating extensive user modifications - points to quality concerns. Perhaps the clearest signal of all is session abandonment, which often reflects user dissatisfaction. These implicit signals offer a comprehensive view across all traffic, unlike explicit ratings, which are typically provided by less than 1% of users in production environments.
Error attribution transforms raw data into actionable insights. By breaking down failures into specific categories rather than treating them as a single issue, teams can address weaknesses more effectively. This approach directly informs retraining efforts and system adjustments, ensuring the model evolves in the right direction.
Ensuring Feedback Quality
Even the most sophisticated monitoring systems are ineffective without reliable feedback. High-quality feedback depends on three factors: volume, broad user coverage, and consistent agreement among annotators. A golden set of 200–500 authoritative examples can help calibrate results, while weak supervision accelerates the labelling process.
"100,000 imperfect labels typically outperform 100 perfect ones. Quantity and coverage dominate precision at the label level." - Tian Pan, Engineer-Founder
Weak supervision is a game-changer, enabling teams to label interaction traces up to 2.8× faster than manual methods. This speed advantage is especially critical when managing high-traffic production systems.
Governance and Documentation
Strong governance ensures feedback loops remain effective and accountable, building on principles of human oversight. A key component is feedback provenance - a detailed record of how feedback was collected, including which annotators provided it, the annotation guidelines in use, and any transformations applied before the data reached the model.
"Feedback provenance is the end-to-end record of how a training signal was assembled... It's the chain of custody that lets you answer: 'If the reward model learned something wrong, where did that wrong signal enter the pipeline?'" - Tian Pan, Engineer-Founder
To document feedback provenance effectively, version transformation logic, maintain detailed decision logs, and publish model cards. These practices not only support internal accountability but also help meet regulatory requirements. For outputs with regulatory or reputational risks, risk-tiered routing can be implemented. This approach allows low-stakes outputs to be auto-approved while critical outputs undergo senior review, reducing human review costs by 40–55% without compromising quality. Additionally, Role-Based Access Control (RBAC) can separate the roles of creating AI outputs and approving them, establishing a clear audit trail.
One governance challenge to anticipate is the "Month Three" stall. Feedback loops often plateau after the initial months as the model absorbs simpler patterns, leaving harder-to-detect errors unresolved. To counter this, active learning - routing uncertain or high-variance interactions to human reviewers - is a proven strategy to keep the system improving rather than stagnating.
Implementing Feedback Loops in Modern Web Applications
Feedback Mechanisms in Digital Products
One of the biggest pitfalls teams encounter when designing feedback systems is relying too heavily on explicit signals. In real-world usage, explicit feedback - like form submissions or survey responses - typically comes from only 1–3% of users. This means the vast majority of users leave no direct feedback at all.
To address this, it's essential to include behavioural proxies alongside explicit feedback options. Actions such as copy-to-clipboard events, retry rates, or the extent of edits made to AI-generated content provide nearly complete coverage without disrupting the user experience. For example, zero edits on AI content suggest strong user satisfaction, while extensive rewrites may highlight underlying issues.
When explicit feedback is collected, simplicity is key. Each additional step in the process dramatically reduces the likelihood of users completing it - completion rates drop by about 50% for every extra action required. A simple "thumbs down" button paired with a quick reason selector (e.g., "too long" or "incorrect information") can yield valuable insights without overburdening users.
This brings us to the architectural considerations necessary to scale such feedback systems effectively.
Architecture Patterns for Scalable Feedback
Building scalable feedback systems requires thoughtful architectural design. Four main layers form the foundation of such systems: the serving layer (API), the logging layer (data warehouse), the evaluation layer (automated checks), and the action layer (triggering updates like retraining models or refining prompts).
To avoid performance issues, feedback collection should occur outside the critical request path. Background processes can handle consistency checks and aggregate metrics without slowing down the application. For data management, a Bronze-Silver-Gold lakehouse model is particularly effective: raw data is stored in Bronze, personally identifiable information is redacted and data is normalised in Silver (using tools like Microsoft Presidio), and curated trend tables are prepared in Gold for monitoring and alerts.
When updating models, a staged promotion process helps mitigate risks. This involves deploying updates in phases: Local → Shadow → Canary → General. Shadow deployments, for instance, allow new versions to run alongside existing production systems, enabling safe testing.
NVIDIA provides a compelling example of this approach at scale. Between August and October 2025, their NVInfo AI system analysed 30,000 employee interactions, categorising failures into routing errors (5.25%) and query rephrasal errors (3.2%). By acting on this structured feedback, NVIDIA replaced a Llama 3.1 70B routing model with a fine-tuned 8B variant. The result? A 96% routing accuracy, a 10× reduction in model size, and a 70% improvement in latency.
These strategies are the backbone of advanced systems, such as those developed by Antler Digital.
How Antler Digital Supports Feedback Loop Implementation

Before adding new components to a system, it's crucial to diagnose existing issues. This principle is central to how Antler Digital helps small and medium-sized enterprises (SMEs) implement AI solutions.
For example, Antler Digital helped a SaaS client reduce churn by 18% by creating a Customer Retention Early-Warning System. This system combined product analytics with support transcripts to identify at-risk customers. Personalised retention offers were then pushed directly into the company’s internal success console and synced with HubSpot. The key to such success lies in gathering feedback that is structured, continuous, and tied directly to actionable business decisions, rather than collecting it in isolation.
"Real AI transformation isn't about making your current processes faster... It's about fundamentally rethinking how your business works." - Antler Digital
On the technical front, Antler Digital builds production-grade systems using tools like Large Language Models (GPT-5, Claude), vector databases (Pinecone, Weaviate), and orchestration platforms (LangChain, Mastra AI). These tools not only improve model performance but also deliver measurable business outcomes, such as better customer retention. By offering end-to-end services - including scoping, design, development, and ongoing management - Antler Digital enables SMEs to integrate robust feedback systems without needing an in-house machine learning engineering team.
Conclusion and Key Takeaways
Summary of Core Concepts
Feedback loops aren't just a bonus - they're the backbone of keeping AI systems relevant and effective over time. Without them, AI models risk becoming stuck in outdated knowledge, falling out of sync as user behaviours and product features evolve. Behavioural signals like copy-paste actions, query rephrasing, and session abandonment help bridge the gap left by explicit ratings, which typically account for only 1–3% of interactions, and they do so without burdening users. Automated evaluation, using LLM-as-judge architectures, takes this a step further by scaling quality monitoring across 100% of production traffic, eliminating the need for a large human review team.
"The difference between AI that stagnates and AI that compounds in value comes down to one thing: whether your organisation treats feedback as a system, not an afterthought." - Glean
Equally important is governance. Feedback needs to be routed correctly - whether to retrieval, prompts, or the model itself - to ensure the appropriate fixes are applied. Trust hinges on timely responses; addressing user-reported errors within 48 hours has been shown to significantly boost adoption, far outweighing the impact of complex pipelines. With these principles in mind, businesses can take actionable steps to maintain and improve AI performance.
Next Steps for Businesses
To get started, businesses should focus on a single, repeatable AI task with a clear outcome signal - for example, a support chatbot, a document classifier, or a content generator. Fully instrument this task by capturing every interaction as a trace, defining what "good" looks like, and setting a specific trigger for action. For instance: "If the helpfulness score falls below 3.0 for two consecutive days, audit the prompt."
From there, businesses can advance through different stages of maturity. Start with manual log reviews, then add explicit feedback collection, incorporate behavioural signals, and finally, implement automated pipelines for feedback curation and model retraining. This approach mirrors the continuous improvement cycle of combining human oversight with scalable automation, as discussed throughout this guide. Cursor's Tab completion model illustrates the potential of this process - it collects real-time acceptance and rejection signals, enabling a full training and deployment loop every 1.5 to 2 hours. While most businesses won't need this level of frequency, the underlying principle is adaptable to varying needs.
For smaller organisations without an in-house machine learning team, Antler Digital provides end-to-end solutions. They handle everything from initial scoping and architecture to ongoing system management, making it possible to build a production-grade feedback system without requiring specialist hires.
FAQs
How do I choose the right feedback signals for my AI product?
To choose the best feedback signals, aim for a balance between value, volume, and friction. Explicit signals, like corrections or thumbs-down responses with explanations, are great for making precise adjustments. Meanwhile, implicit signals, such as analysing user behaviour patterns, work well for large-scale monitoring with minimal disruption. Ensure the signals align with your objectives and make it simple for users to share feedback. By combining explicit and implicit signals, you can achieve both detailed fine-tuning and wide-reaching quality checks to enhance AI performance effectively.
When should humans review AI outputs, and when can it be automated?
Humans play a critical role when it comes to reviewing AI outputs in high-stakes, high-risk, or uncertain situations. These can include cases where confidence in the AI's predictions is low, decisions involve significant financial or operational value, or when dealing with sensitive material. On the other hand, for routine tasks or low-risk scenarios, automation is usually sufficient. Striking this balance helps maintain efficiency while ensuring accountability in processes driven by AI.
How can I collect feedback and retrain models without breaking GDPR?
To meet GDPR requirements, prioritise data minimisation, anonymisation, and pseudonymisation in your processes. Where feasible, incorporate synthetic data to reduce reliance on personal information. Always collect personal data with explicit consent and ensure it serves clearly defined purposes.
Keep data streams separate, implement mechanisms for data erasure, and adopt privacy-focused methods such as federated learning. Consistently document the origins of data, feedback workflows, and updates to models. This not only helps demonstrate compliance but also supports ongoing improvements in AI systems.

Lets grow your business together
At Antler Digital, we believe that collaboration and communication are the keys to a successful partnership. Our small, dedicated team is passionate about designing and building web applications that exceed our clients' expectations. We take pride in our ability to create modern, scalable solutions that help businesses of all sizes achieve their digital goals.
If you're looking for a partner who will work closely with you to develop a customized web application that meets your unique needs, look no further. From handling the project directly, to fitting in with an existing team, we're here to help.